Jahrestagung der Gesellschaft für Medizinische Ausbildung
Large Language Modelle zur automatisierten qualitativen Inhaltsanalyse von Freitextantworten aus der Lehrevaluation: Genauigkeit und qualitative Unterschiede im Vergleich zur manuellen Analyse
Text
Fragestellung/Zielsetzung: Studentische Evaluationen sind in der medizinischen Ausbildung weit verbreitet [1]. Die Auswertung von Freitextantworten erfordert große personelle und zeitliche Ressourcen [1], sodass deren Analyse mit Large Language Modellen (LLMs) wie GPT-4 erprobt wurde [2], [3]. Ziel dieser Arbeit ist die Entwicklung eines allgemeinen Workflows zur automatisierten inhaltlich strukturierenden qualitativen Inhaltsanalyse (QIA) von Freitextantworten mittels LLM. Dabei sollen die Genauigkeit vergleichend zu einer manuellen Inhaltsanalyse mittels Inter-Rater Reliabilität (IRR) bestimmt, qualitative Unterschiede beider Analysemethoden ermittelt, sowie Methoden zur Verbesserung der Genauigkeit erarbeitet werden.
Methoden: Aus der Evaluation des Praktischen Jahres (PJ) am LMU Klinikum wurden Freitextantworten auf drei offene Fragen mittels QIA ausgewertet (n=272, 02.2023-03.2024). Die Kodierschemata wurden induktiv-deduktiv entwickelt und durch zwei Kodierpersonen (KP) an 20% des Materials hinsichtlich der IRR überprüft. Die automatisierte QIA wurde in R mittels gpt-4o-2024-08-06 realisiert. Dazu wurde ein Chain-of-Thought Prompt mit den Kodierschemata aus der manuellen QIA iterativ entwickelt. In der LLM-Analyse wurde zunächst jede Antwort einzeln analysiert. Dies wurde im finalen Workflow um eine automatische Selbstkorrektur (SK) Schleife erweitert, die zu einer automatischen Wiederholung der Analyse mit Feedback bei Fehlern führt (siehe Abbildung 1 [Fig. 1]). Die Ergebnisse wurden in MAXQDA übertragen und mit der manuellen QIA verglichen.
Abbildung 1: Qualitative Inhaltsanalyse (QIA): Workflow mit Selbstkorrekturschleife (SK)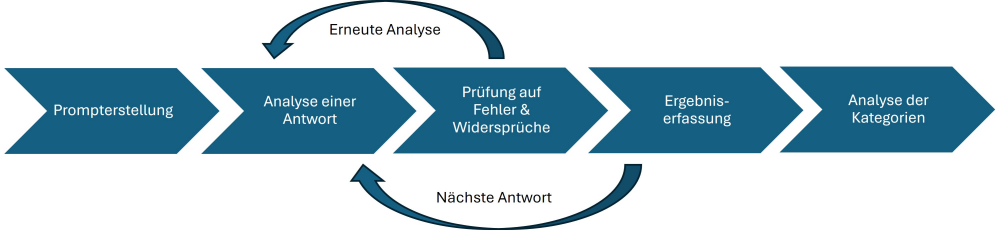
Ergebnisse: Die IRR zwischen beiden KP lag bei 0.9-0.95, zwischen den KP und dem LLM bei 0.57-0.75. Die Anwendung von SK führte bei allen Fragen zu einer Erhöhung der IRR um etwa 0.1 (0.72-0.91). Bei Abweichungen der LLM-Kodierung von den KP waren Widersprüche in der Begründung des LLMs auffällig. Bei Unstimmigkeiten zwischen den Kodierenden waren in der LLM-Kodierung teils mehrere SK-Schleifen erforderlich. Zudem wurden vier Fehler der KP durch das LLM aufgedeckt. Trotz wiederholter Optimierung der Prompts und Abläufe, wurden durch das LLM nichtzutreffende Kodierungen vorgenommen und relevante Kodierungen ausgelassen.
Diskussion: LLMs können in der QIA angewendet werden. Die Genauigkeit der LLM-Kodierungen wurde durch SK-Schleifen deutlich verbessert und eine menschenähnliche Präzision erreicht. Manuelle QIA könnten außerdem durch die Identifikation von Fehlern und herausfordernden Rückmeldungen erleichtert werden. Die Implementierung dieses Workflows zur standardisierten automatisierten QIA der Freitextantworten der PJ-Evaluation könnte Wegbereiter für eine generelle automatisierte Auswertung von Freitextantworten aus Lehrevaluationen sein.
Take Home Message: Zusammenfassend zeigte sich, dass LLMs zur Automatisierung von QIA anhand von vordefinierten Kodierschemata mit menschenähnlicher Genauigkeit einsetzen lassen und SK-Schleifen die Genauigkeit deutlich verbessern.
References
[1] Richardson JT. Instruments for obtaining student feedback: a review of the literature. Assess Eval High Educ. 2005;30(4):387-415. DOI: 10.1080/02602930500099193[2] Parker MJ, Anderson C, Stone C, Oh Y. A Large Language Model Approach to Educational Survey Feedback Analysis. Int J Artif Intell Educ. 2025;35:444-481. DOI: 10.1007/s40593-024-00414-0
[3] Fuller KA, Morbitzer KA, Zeeman JM, Persky AM, Savage AC, McLaughlin JE. Exploring the use of ChatGPT to analyze student course evaluation comments. BMC Med Educ. 2024;24(1):423. DOI: 10.1186/s12909-024-05316-2

