28. Jahrestagung der Deutschen Gesellschaft für Audiologie e. V.
Beyond Beamforming: KI-basierte Sprechertrennung in Echtzeit mit Einkanalmessungen
Text
Fragestellung: Das sogenannte Cocktail-Party-Problem beschreibt die Herausforderung, in lauten Umgebungen mit mehreren Sprechern einem bestimmten Zielsprecher zu folgen. Für Träger von Hörgeräten und Cochlea-Implantaten ist dies oft sehr schwierig. Bisherige Verfahren zur Rauschunterdrückung im akustischen Signal wie „Beamforming“ können mittels mehrerer Mikrophone die Sprachverständlichkeit verbessern. Tiefe neuronale Netzwerke erreichen sogar mit Einkanalmessungen erhebliche Rauschunterdrückung. Wir entwickeln hier ein KI-basiertes-Echtzeit-Verfahren zur Sprechertrennung, welches mit nur einem Mikrofon funktioniert.
Methoden: Implementiert wurde ein System zur Blind Source Separation (BSS), das kontinuierliche Audiodaten in 0,5s-Fenstern verarbeitet. Es wurden drei verschiedene Instanzen von KI-Modellen getestet, die über ein FastAPI/ONNX/OpenVINO-Framework implementiert wurden: TDANet [1], TIGER-tiny [2] und TIGER-full [2]. Die auf englischen Daten vortrainierten KI-Modelle wurden für die Echtzeitanwendung optimiert und auf deutsche Audiodaten angewandt. Diese enthielten zwei simultane Sprecher mit jeweils einer männlichen und einer weiblichen Stimme [3]. Die Qualität der Sprechertrennung wurde mittels SI-SDR, STOI und PESQ in jeweils 5s-Fenstern gemessen. Ein WebAudio-Frontend mit AudioWorklets übernahm Streaming, Wiedergabe und Visualisierung in Echtzeit, vollständig im Browser und ohne spezielle Hardware.
Ergebnisse: Die Echtzeitverarbeitung kontinuierlicher Audiodaten wurde auf handelsüblichen Laptops (ohne GPU) erfolgreich implementiert. In allen Metriken zur Sprachverständlichkeit- und -qualität stach TIGER-full mit den besten Ergebnissen hervor (Abbildung 1 [Abb. 1]). Im Mittel erreicht TDANet eine SI-SDR von 4,86 ± 4,39 dB, TIGER-tiny 10,01 ± 1,66 dB und TIGER-full 14,25 ± 1,30 dB. Gepaarte t-Tests zeigen, dass für SI-SDR beide TIGER-Modelle das TDANet-Modell hochsignifikant übertreffen (p < 0,001; große Effektstärken nach Cohen’s d). Darüber hinaus ist auch der Unterschied zwischen TIGER-tiny und TIGER-full hochsignifikant (p < 0,001). Ein analoges Bild zeigt sich für STOI und PESQ, wobei TIGER-full durchgängig die höchsten Werte erzielt. Aufgrund der erhöhten Komplexität der Tiger-Modelle, hat das TDANet allerdings den Vorteil, dass es sich besser für die Anwendung auf CPUs optimieren lässt und deshalb aktuell die niedrigsten Latenzen von unter 300ms erreicht.
Abbildung 1: KI-Modellvergleich (Param, SI-SDR, STOI, PESQ)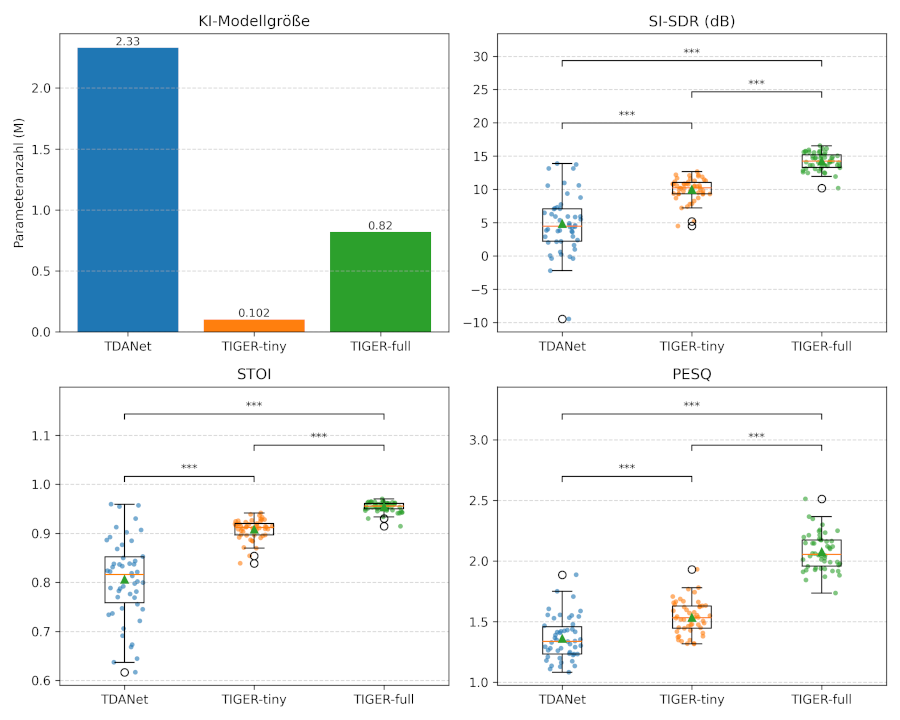
Schlussfolgerungen: Die Kombination aus effizienter Modelloptimierung und webbasierter Architektur ermöglicht eine Echtzeit-Sprechertrennung mit nur einem Mikrofon. Das Konzept bietet das Potenzial, in zukünftigen intelligenten Hörgeräten und CIs eine KI-gestützte Trennung verschiedener Sprecher direkt im Nutzergerät zu realisieren. Aktuell wird an der weiteren Optimierung der Modell-Latenzen gearbeitet, um sie auch auf Endgeräten mit geringer CPU-Leistung realisieren zu können und somit alltagsrelevant werden zu lassen.
References
[1] Li K, Yang R, Hu X. An efficient encoder-decoder architecture with top-down attention for speech separation. In: The 11. Int. Conf. on Learning Representations. 2023.[2] Xu M, Li K, Chen G, Hu X. TIGER: Time-frequency Interleaved Gain Extraction and Reconstruction for Efficient Speech Separation. In: International Conference on Learning Representations (ICLR). 2025.
[3] Jehn C, Kossmann A, Katerina Vavatzanidis N, Hahne A, Reichenbach T. CNNs improve decoding of selective attention to speech in cochlear implant users. J Neural Eng. 2025 Jun 10;22(3). DOI: 10.1088/1741-2552/addb7b

