28. Jahrestagung der Deutschen Gesellschaft für Audiologie e. V.
Entwicklung eines blinden Echtzeit-Modells für Sprachverständlichkeit und subjektive Höranstrengung für den Einsatz in Hörgeräten
Text
Viele Modelle für Sprachverständlichkeit (SVS) und/oder Höranstrengung (HA) wurden in den vergangenen Jahrzehnten entwickelt und werden für verschiedene Zwecke eingesetzt. Typischerweise arbeiten solche Modelle offline und sagen z.B. für einen Satz Sprache im Störgeräusch einen einzigen SVS- oder HA-Wert vorher. Darüber hinaus nutzen die meisten Modelle Referenzsignale oder getrennte Sprach- und Störsignale für die Vorhersage. In einigen Anwendungsbereichen werden Vorhersagen jedoch sehr frequent und ohne Verfügbarkeit von reinen Quellsignalen benötigt, d.h. die Modelle müssten in Echtzeit und blind arbeiten. Blinde und echtzeitfähige Vorhersagen von SVS oder HA könnten beispielsweise für Hörgeräte wertvoll sein, die mittels dieser Information z.B. für eine gegebene Hörsituation das gerade am besten geeignete Hörgeräte-Programm automatisch auswählen könnten. Ein solches Modell für diesen Anwendungsfall sollte zudem den individuellen Hörverlust berücksichtigen.
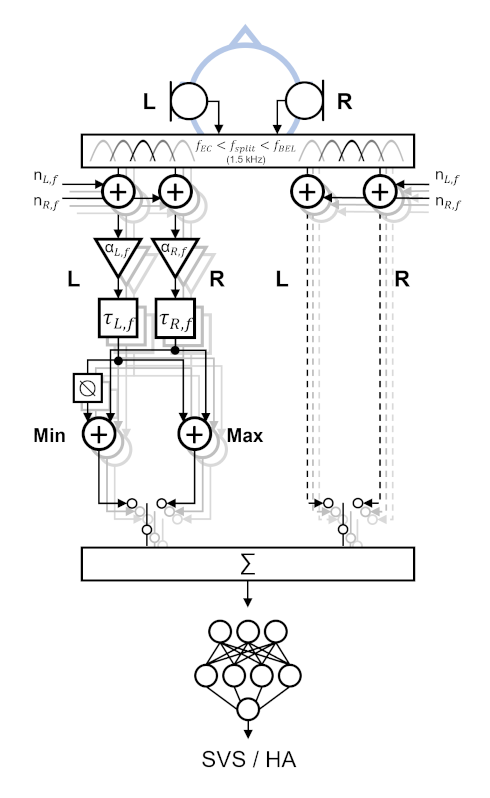
Ein blindes und echtzeitfähiges Modell zur Vorhersage von SVS und HA wurde entwickelt, das zudem unterschiedlich schwerwiegende Hörverluste berücksichtigt. Das Modell besteht aus zwei Stufen: einem Front-End zur Simulation der binauralen Fähigkeiten des Menschen und einem Back-End zur Schätzung von SVS und HA, basierend auf dem Output des Front-Ends. Das Front-End filtert zunächst die Ohrsignale mit einer auditorischen Filterbank und wendet ein schwellensimulierendes Rauschen an, welches das Audiogramm nachbildet, um den Effekt des jeweiligen Hörverlusts zu simulieren. Anschließend wird parallel ein Equalization-Cancellation-Mechanismus für auditorische Filter mit Mittenfrequenzen unterhalb von 1,5 kHz und „Better-Ear-Listening“ für auditorische Filter mit Mittenfrequenzen oberhalb von 1,5 kHz angewendet. Das auf diese Weise binaural verarbeitete einkanalige Ausgangssignal wird dann durch das Back-End verarbeitet, welches einen Triphon-Klassifikator zur Vorhersage von SVS und HA anwendet.
Das Modell wurde anhand von Daten evaluiert, die durch ein neuartiges Echtzeit-Messverfahren erhoben wurden, wobei normalhörende Versuchspersonen kontinuierlich die subjektiv wahrgenommene HA in dynamisch simulierten Szenen bewerteten. Das Modell konnte die subjektive HA mit hoher Genauigkeit (R² = 0,87) für Bedingungen vorhersagen, in denen das Signal-Rausch-Verhältnis (SNR) und/oder die Nachhallzeit variiert wurden. Darüber hinaus wurde das Modell mit bestehenden Datensätzen validiert, die HA für sehr leise Sprache sowie Daten mit hörgeschädigten Versuchspersonen umfassen.
Abbildung 1 [Abb. 1]